Statistics and Data Science
Work within this theme includes a wide range of exciting research topics, including environmental hazards, air quality modeling, calibration of computer models, forecast verification and spatial epidemiology. We teach Statistics at all levels, covering a range of applied and theoretical topics.
Research interests
Forecast post-processing
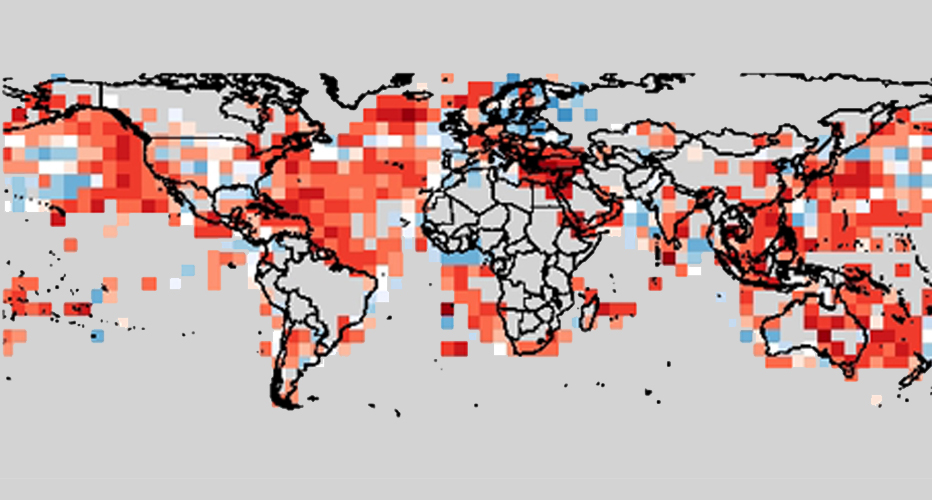
Computer models of atmospheric physics used for weather and climate prediction are only imperfect representations of the real world.
We develop statistical modelling techniques to correct systematic forecast biases resulting from structural model errors, to improve the skill and reliability of weather and climate forecasts.
Selected publications: Siegert et al. (2016), Sansom et al. (2016).
Forecast verification
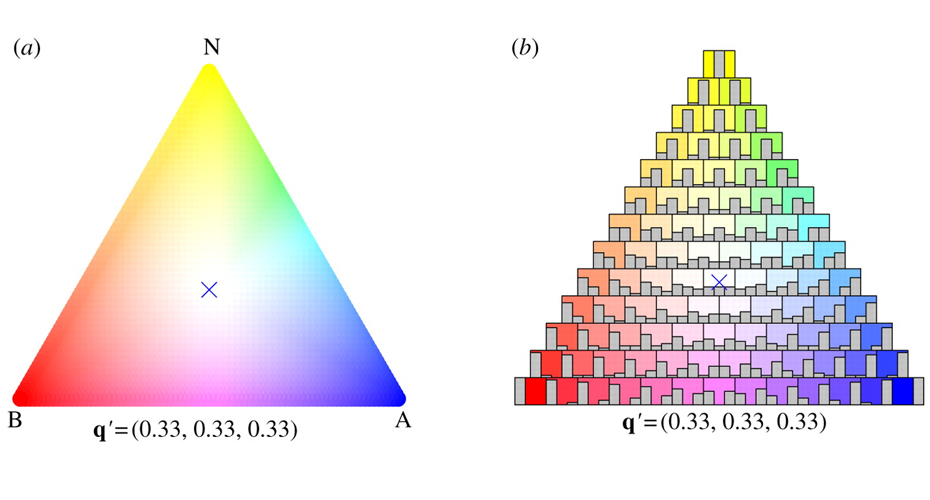
Forecast evaluation is about assessing the performance of forecasts by comparing past forecasts to observations. Evaluating forecasts can be difficult because a) there are many different types of forecast (point forecasts, probability forecasts, interval forecasts, ensemble forecasts), and b) there are many ways in which a forecast can be wrong.
A careful and informative assessment of forecast quality can help to guide decision making, to monitor changes in performance, and to improve forecasts across a wide range of fields, such as economics, finance, health, hydrology, and meteorology.
Selected publications: Jupp et al. (2012), Ferro et al. (2008), Fricker et al. (2013), Ferro (2014), Siegert (2017)
Calibration of computer models
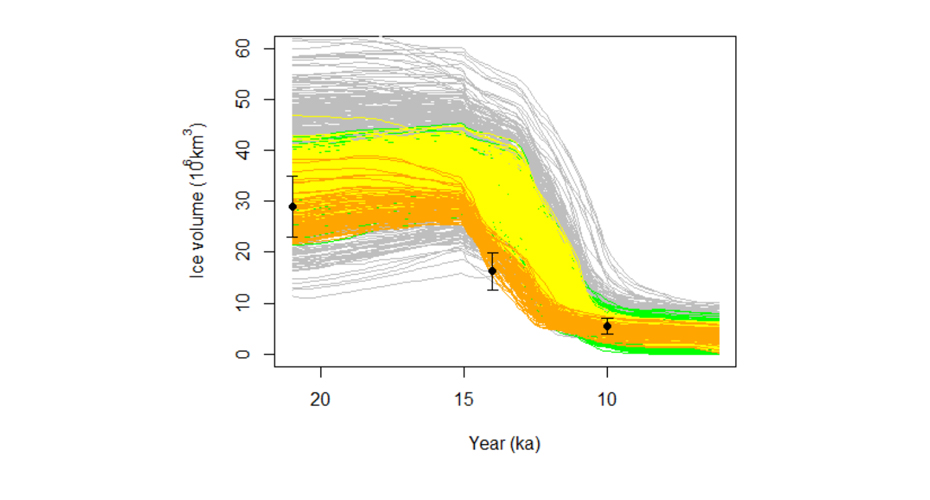
In order to have confidence in computer model output of complex systems such as the climate system, the model inputs must be tuned (‘calibrated’) so that the model outputs match historical observations. However, running complex simulation models is computationally expensive and the space of possible input parameter is large, which complicates direct calibration.
Our group develops uncertainty quantification methodology for probabilistic calibration and history matching, to establish optimal input parameters for the computer model to produce realistic output.
Selected publications: Salter et al. (2018)
Environmental hazards
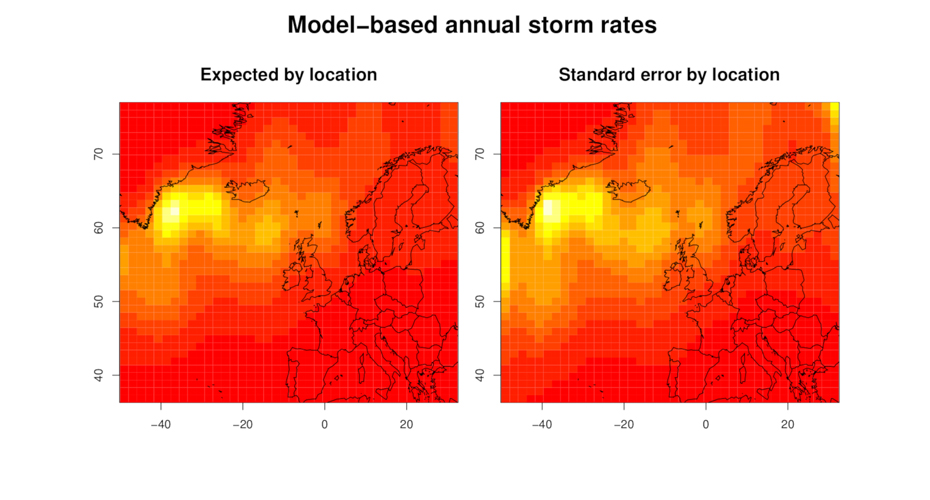
We have a world-renowned track record in the quantification of risk due hydro-meteorological hazards responsible for large insurance losses, and in the visualisation and communication of the associated uncertainty.
We are particularly interested in hazards associated with intense extratropical cyclones, hurricanes, extreme rainfall, and floods.
Using techniques from dynamical systems theory, extreme value theory, climate science, and spatial statistics we aim to improve fundamental understanding and prediction of severe weather and its impact on society.
Selected publications: Youngman & Stephenson (2016), Youngman & Economou (2017), Xiong et al. (2021)
Air quality modelling
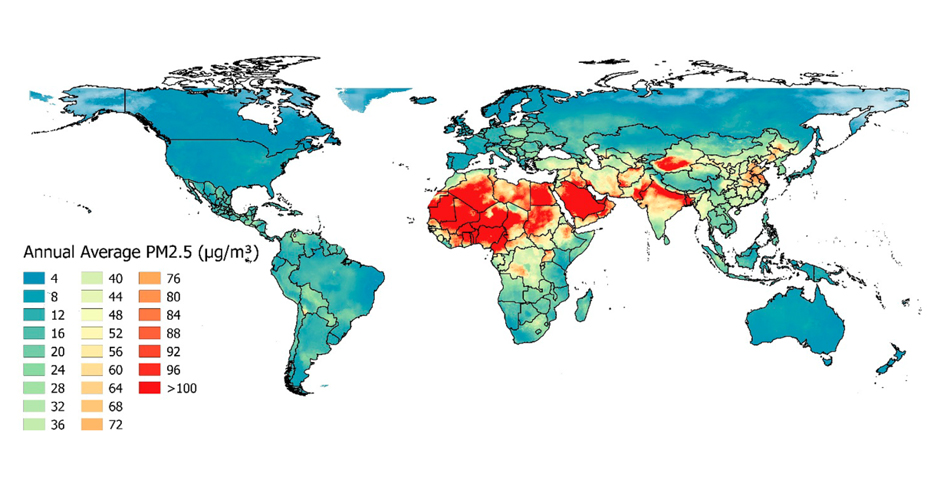
Air pollution is a leading global disease risk factor, and tracking progress requires accurate, spatially resolved exposure estimates.
We develop statistical methodology to integrate large amounts of data from numerous sources (satellites, station measurements, indirect predictors) to estimate air pollution at high spatial and temporal resolutions.
Selected publications: Shaddick et al (2017)
Spatial epidemiology
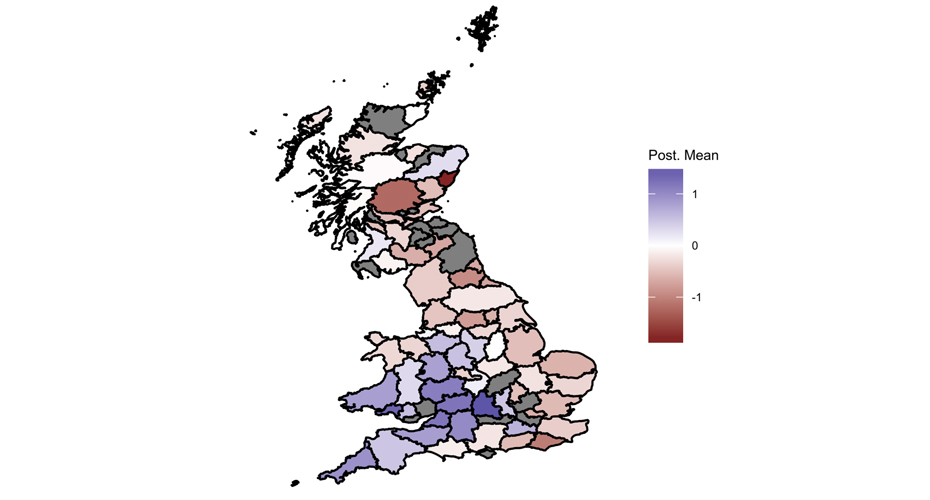
We develop disease risk prediction models to assist in public health decision making, using spatial, temporal and space-time statistical modelling including Bayesian hierarchical modelling and MCMC techniques.
One of the special interests in the group is the incorporation of dynamical climate models into statistical models of disease risk, to predict climate-related health hazards such as heat-wave mortality or the effect of climate on the spread of vector-borne diseases.
Selected publications: McKinley et al. (2018)
Uncertainty quantification in complex systems
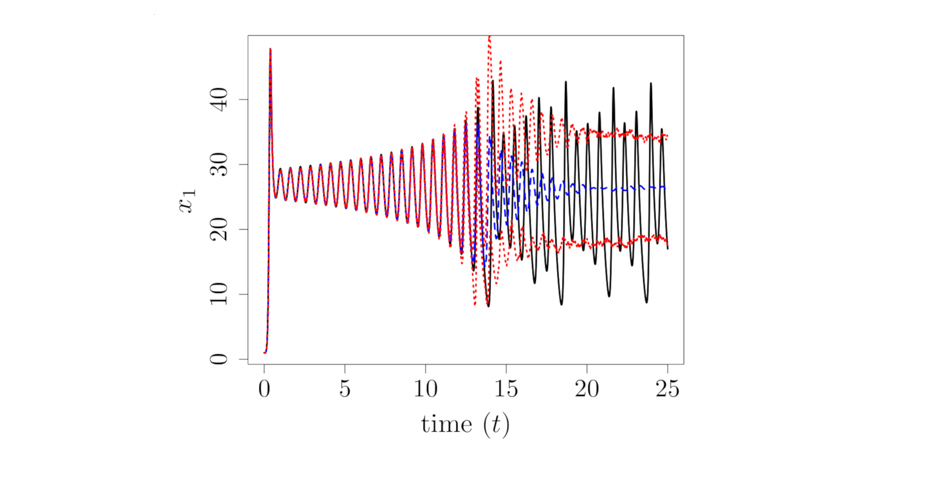
We develop statistical methodologies to quantify uncertainties when phenomena in the real-world are described by complex computer models in fields such as hydrology, manufacturing, energy, finance and geosciences. Propagating uncertainties from the unknown model inputs to the model outputs requires thousands of evaluations of the model at different input parameters, which is impossible if a single model run takes days or even weeks on a supercomputer.
Statistical surrogate models (‘emulators’), that can be run cheaply in place of the computationally expensive complex model, allow us to obtain a complete picture of the uncertainties related to the models fidelity and robustness, and extract more reliable predictions from the computer model.
Selected publications: Mohammadi et al. (2018)
People and partners
See the drop-down menus below to find out more about the staff members who work within the Statistics and Data Science theme, and which modules they teach.























We are an interdisciplinary group and collaborate closely with various science groups and institutes from the University of Exeter:
- Exeter Climate Systems
- Q-Step
- Institute of Data Science and Artificial Intelligence (IDSAI)
- Geophysical and Astrophysical Fluid Dynamics
- Living Systems Institute
We maintain strong links with external research institutions, government agencies and industry partners:
Currently open PhD studentships
- Faculty-funded studentships
- Bullwhip Effect in Supply Chains (supervised by Chaitra Nagaraja, Stephen Disney and Theo Economou). For an informal discussion contact the lead supervisor at c.nagaraja@exeter.ac.uk.
- Statistical modelling for single-cell RNA sequencing data for crucial health applications (supervised by Magdalena Strauss, Askhay Bhinge and Marc Goodfellow). Apply by 16th March. For an informal discussion contact the lead supervisor at m.strauss@exeter.ac.uk.
Interested in a PhD in statistics and data science at Exeter?
Members of the Statistics and Data Science group are happy to discuss potential PhD opportunities. Jobs within this group will be posted on the University job portal.
Postgraduate research opportunities
The Statistics and Data Science group at Exeter maintains an international reputation for research and we continue to invest in top-quality academics and offer a range of projects to research students to enhance this expertise. For more details of our facilities and training programmes, see our pages for postgraduate taught and postgraduate research degrees.
Apply for a research degree in mathematics
Details of research opportunities within mathematics are listed on our webpage. A list of projects for which funding is currently available can be found on our dedicated studentship webpage.
If you are interested in doing a PhD in statistics and data science, please contact potential supervisors to discuss possible projects. You can find out more and apply on our website.


For questions and enquiries please use the following contacts:
- Academic lead: Theo Economou
- Statistics and Data Science seminars: Dr Victoria Volodina and Dr Hossein Mohammadi
- Website: Dr Ben Youngman and Dr Theo Economou
Find out more


